Week 3 - Lots of code and learning
Week 3 was filled with more of coding and learning new things down the line. I learned how dependency injection in Golang is done, writing mocks and stubs for the test cases, etc. to name a few. How an application is deployed to tens of servers with the push of a button.
To know what I’m building head over to week 2’s post here if you haven’t already.
Day 1
Mudit was deploying an incremental update to one of the services that power the Go-Food stack at GoJek. I asked him if I can join and he was happy to show me how it’s done. The scale at which GoJek works and how a single engineer is responsible for half a million user’s requests is mind-boggling. When you have that kind of requests coming in every second you can’t afford your systems to go down even for a blink of an eye.
There are several layers through which a request goes and one of them is the load balancer layer, HAProxy is used in this case. So every request falls on to HAProxy and then it is diverted to one the application servers for the request to be processed. GoJek has quite a number of them and when an update is deployed, it is deployed to one application server at a time. This way the other servers are still up to serve the requests coming in.
Although to deploy an update you need to inform other concerned teams about it and create a document mentioning what changes it is going to make, what other services will it affect, etc? Once the teams are informed over internal IM, there are a few monitoring services to be fired up in order to track any undesired effect during the rollout.
The actual rollout is very easy because it is all automated. You just click a button and boom, the deployment starts one-by-one on every machine in the stack. Since the code is added, refactored and changed at blazing speeds here, we need such Continuous Integration and Continuous Deployment tools to keep us going without a bottleneck. More on the process in Day 4.😉

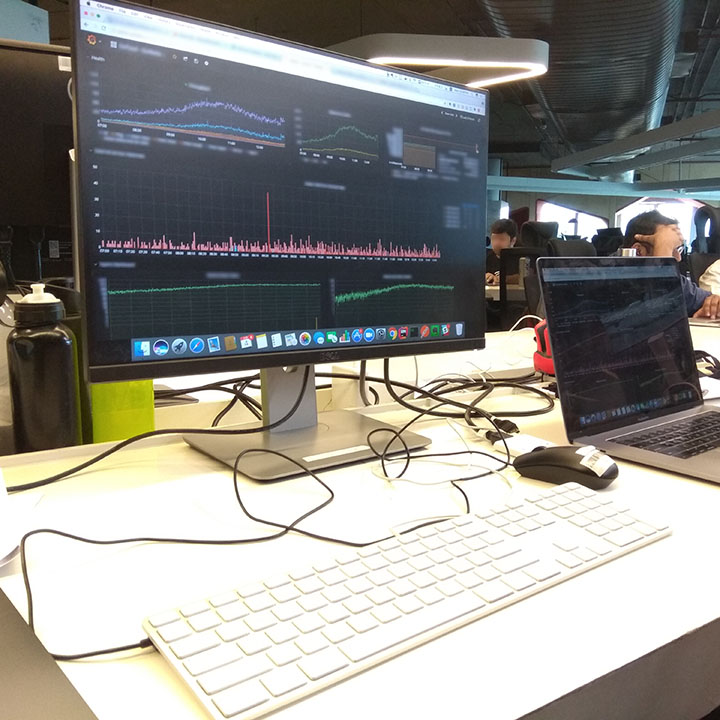
The deployment was successful and the new feature was up and the Apdex score was satisfactory. It took hardly 15-20 mins in the whole process without any decrease in the overall throughput of the application requests coming in. We worked on our own project for the rest of the day.
Day 2-3
I and Rajat started working on the handler that’ll serve the images after processing them, we wrote some tests and then wrote the code for the handler. We stubbed the function that’ll actually process the image but it wasn’t feeling right to go top-down, so we decided to go bottom-up and started working on the ImageProcessor service first and we chose to implement resize capability first. We’re using imagick library which provides Go bindings to the underlying ImageMagick’s MagickWand C API.
We faced a lot of problems because the image object was being mutated in different parts of the existing code. And we had to also save the processed image back to the S3 bucket but with a new UUID which has to be generated based on an SHA-1 hash of the ordered query string that was used to process the image so that we never process one image again and again.
We implemented the resize and crop capability and it was working as expected. We then linked these new image processing capabilities to the handler that’ll actually serve the requests on the next day and tested it locally. But we had made a mess as we wrote all the code inside the handler itself. The next task was to fix the code smell.
Day 4
It was now time to introduce a new decision-making service that’ll take in the requested image’s name and the query parameters and based on the data it’ll decide what to do and call the image processor to actually process the image. I had to use some of the existing services and since I was practicing TDD, I had quite a hard time in stubbing the existing services.
I was writing tests for a function and had to call the same function twice inside the decision-making service but wanted it to behave differently based on the input I was giving to the function. That’s when I came across mocks in Golang and how they provide additional ways to ease the task of testing. Dependency injection was very important in this part as I had to use some of the existing services inside the new service while practicing TDD.😅
Learning session
Puneet held a learning session in which I learned how actually the deploying process works, what happens inside all this one click voodoo that deploys your app automatically. There’s a Chef, a knife, a cookbook, and many recipes. Yes, they’re actually named like this.
 A chef knows everything, it is a server which is used to communicate during the deployment process and tells the chef-clients what to do. Every VM has a chef-client which is instructed to pick up a cookbook and start the deployment. A cookbook is nothing but contains the information on how to build an application, just like an actual cookbook has recipes for dishes. Now the individual recipes are analogous to applications.
A chef knows everything, it is a server which is used to communicate during the deployment process and tells the chef-clients what to do. Every VM has a chef-client which is instructed to pick up a cookbook and start the deployment. A cookbook is nothing but contains the information on how to build an application, just like an actual cookbook has recipes for dishes. Now the individual recipes are analogous to applications.
Let’s say your application needs database. You can avoid all the pain to set up the database server and just include the postgresql or mysql recipe and voila, chef-client does it for you. Same happens with your own application, you just need to specify a recipe on how to build the app.
Day 5
We added some analytics utilities to the code in order to track the performance and any other potential errors. Sainath also added the ability to turn an image all black and white. Deepesh made some adjustments and merged our branch into master and deployed the new code to integration environment where it’ll be tested thoroughly in the coming days.
The next step is to load test our image processing service, after all, it has to handle 50K rpm!
